
웹 개발자가 되려면 크롤링은 어느정도 할 줄 알아야 한다고 생각합니다.
그래서 오늘은 크롤링에 대해 공부해보려고 합니다.
웹 크롤링이란?
웹 크롤링(Web Crawling)은 웹 사이트에서 데이터를 자동으로 수집하는 기술을 의미합니다.
이를 통해 웹 상의 다양한 데이터를 가져와 가공할 수 있죠.
주요 라이브러리
웹 크롤링을 하기 위한 보편적인 라이브러리 몇 가지만 소개하겠습니다.
| 라이브러리 | 기능 |
| requests | 웹 페이지 HTML 가져오기 |
| BeautifulSoup | HTML을 파싱(분석)하여 원하는 데이터 추출 |
| Selenium | 동적인 웹 사이트(JavaScript 기반) 크롤링 |
| pandas | 크롤링한 데이터를 저장하고 분석하는데 활용 |
| scrapy | 대규모 크롤링을 위한 프레임워크 |
정적 vs 동적?
웹 크롤링은 크게 정적 크롤링과 동적 크롤링으로 나눌 수 있습니다. 차이점은 웹 페이지의 내용이 어떻게 로드되는지에 따라 달라집니다.
1. 정적 크롤링 (Static Crawling)
정적 웹 페이지는 페이지의 모든 콘텐츠가 HTML 파일로 서버에서 클라이언트로 전송됩니다. 이 HTML 파일에는 페이지의 모든 텍스트, 이미지, 링크 등 필요한 정보가 포함되어 있습니다.
정적 크롤링은 페이지가 완전히 로드된 상태에서 HTML 코드만을 읽어들이는 방식입니다. JavaScript나 다른 클라이언트 코드가 실행되지 않아도 데이터를 바로 추출할 수 있습니다.
정적 페이지 예시: 블로그, 뉴스 사이트, 기업 웹사이트 페이지 등
2. 동적 크롤링 (Dynamic Crawling)
동적 웹 페이지는 JavaScript 등을 사용하여 페이지 로딩 후 추가적인 콘텐츠를 클라이언트 측에서 동적으로 로드하는 웹 페이지입니다. 즉, 서버에서 초기 HTML 파일만 보내고, 그 후에는 JavaScript 코드가 실행되어 페이지의 나머지 콘텐츠를 추가로 로드합니다.
동적 크롤링은 이 JavaScript로 생성된 콘텐츠까지도 크롤링해야 하므로, 크롤러가 페이지를 완전히 로드할 때까지 기다리고 JS를 실행할 수 있어야 합니다.
동적 페이지 예시: 소셜 미디어, 쇼핑몰, 지도 서비스 등
정적 크롤링 실습
입력한 키워드가 포함된 네이버 뉴스의 제목과 url을 가져오는 실습을 진행해보겠습니다.
먼저, 필요한 라이브러리 설치를 위해 VSCode의 터미널 창에 아래 명령어를 입력하여 라이브러리를 설치합니다.
pip install beautifulsoup4 requests
실습에 필요한 라이브러리를 import 해줍니다.
from bs4 import BeautifulSoup as bs
import requests
검색할 키워드를 입력받고 query 변수에 넣어줍니다.
query = input('검색할 키워드를 입력하세요: ')
네이버 뉴스 검색 URL에 사용자가 입력한 키워드를 넣어서 URL을 만들어줍니다.
url = 'https://search.naver.com/search.naver?where=news&sm=tab_jum&query='+'%s'%query
requests 패키지를 이용해 해당 URL에서 HTML 데이터를 가져옵니다.
가져온 HTML 문서를 문자열로 저장하여 html_txt 변수에 넣습니다.
response = requests.get(url)
html_text = response.text
BeautifulSoup 패키지로 파싱 후, 'soup' 변수에 저장합니다.
soup = bs(response.text, 'html.parser')
네이버 뉴스 페이지에서 기사 제목을 감싸고 있는 <a> 태그를 선택하여 news_titles 리스트에 저장합니다.
news_titles = soup.select("a.news_tit")# 뉴스 제목을 감싸고 있는 HTML 구조 예시
<a href="뉴스링크" class="news_tit" target="_blank" title="기사 제목">
기사 제목
</a>
<a> 태그 안의 텍스트(기사 제목)만 추출하여 출력합니다.
for i in news_titles:
title = i.get_text()
print(title)
뉴스 링크를 크롤링하기 위해 <a> 태그의 href 속성 값(뉴스 기사 URL)을 추출하여 출력합니다.
for i in news_titles:
href = i.attrs['href']
print(href)
정적 크롤링 - 전체 코드
from bs4 import BeautifulSoup as bs
import requests
# 검색할 키워드 입력
query = input('검색할 키워드를 입력하세요: ')
# 네이버 뉴스 검색 URL 생성
url = 'https://search.naver.com/search.naver?where=news&sm=tab_jum&query='+'%s'%query
# HTML 문서 가져오기
response = requests.get(url)
html_text = response.text
# HTML 파싱
soup = bs(response.text, 'html.parser')
# 뉴스 제목 크롤링
news_titles = soup.select("a.news_tit")
# 뉴스 제목 출력
for i in news_titles:
title = i.get_text()
print(title)
# 뉴스 URL 크롤링 출력
for i in news_titles:
href = i.attrs['href']
print(href)
동적 크롤링 실습
구글 트렌드 페이지에서 실시간 인기 검색어를 가져오는 실습을 해보겠습니다.
먼저, 필요한 라이브러리 설치를 위해 똑같이 아래 명령어를 입력하여 설치합니다.
pip install selenium
pip install webdriver-manager
실습에 필요한 라이브러리를 import 해줍니다.
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from webdriver_manager.chrome import ChromeDriverManager
import time
webdriver-manager 라이브러리를 사용하여 자동으로 크롬 드라이버를 다운로드하고, 서비스로 실행합니다.
크롬 브라우저를 자동으로 실행하여 driver 객체를 생성합니다. 이후 driver를 통해 브라우저를 제어할 수 있습니다.
service = Service(ChromeDriverManager().install())
driver = webdriver.Chrome(service=service)
구글 트렌드 페이지의 URL을 가져와줍니다.
driver.get(url)을 통해 Selenium WebDriver는 브라우저에서 해당 URL로 접속합니다.
url = "https://trends.google.com/trends/trendingsearches/daily"
driver.get(url)
페이지가 완전히 로드되도록 3초간 대기해줍니다.
time.sleep(3)
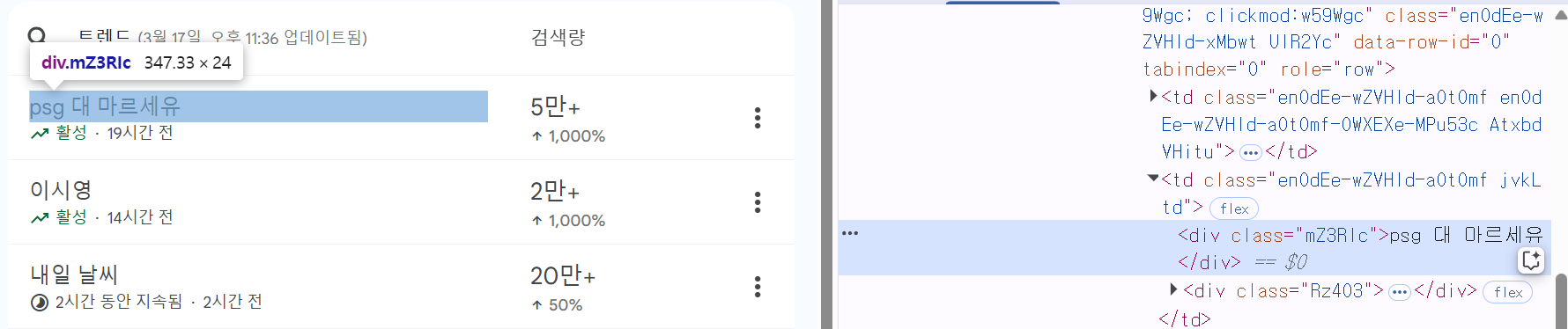
크롤링할 URL에 들어가서 F12를 누른 다음, Ctrl+Shift+C를 클릭하고, 인기 검색어 제목을 클릭하면, 해당 위치의 HTML을 확인할 수 있습니다. 여기서 class 태그의 값인 ".mZ3RIc"를 적어주면, 이에 해당하는 모든 요소들을 찾습니다.
search_keywords = driver.find_elements(By.CSS_SELECTOR, ".mZ3RIc")
serch_keywords 리스트에서 인덱스와 값을 함께 순회합니다. start=1로 설정했기 때문에 인덱스는 1부터 시작합니다.
print("@@구글 트렌드 인기 검색어@@")
for idx, keyword in enumerate(search_keywords, start=1):
print(f"{idx}. {keyword.text}")
브라우저를 종료하고 Selenium WebDriver 세션을 종료합니다.
driver.quit()
동적 크롤링 - 전체 코드
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from webdriver_manager.chrome import ChromeDriverManager
import time
# 크롬 드라이버 실행
service = Service(ChromeDriverManager().install())
driver = webdriver.Chrome(service=service)
# 구글 트렌드 페이지 접속
url = "https://trends.google.com/trends/trendingsearches/daily"
driver.get(url)
# 페이지 로딩 대기
time.sleep(3)
# 인기 검색어 크롤링
search_keywords = driver.find_elements(By.CSS_SELECTOR, ".mZ3RIc")
# 인기 검색어 리스트 출력
print("@@구글 트렌드 인기 검색어@@")
for idx, keyword in enumerate(search_keywords, start=1):
print(f"{idx}. {keyword.text}")
# 웹드라이버 종료
driver.quit()
막혔던 점
웹 크롤링을 공부하면서 직접 코드를 작성하고 실행해보는 과정에서 문제가 발생했다.
코드를 실행했을 때 결과가 터미널에 출력되지 않는 것이다.
처음에는 코드가 잘못된 줄 알고 여러 크롤링 예제들을 참고해서 고치고 또 고쳤다.
혹시 라이브러리가 정상적으로 설치되지 않은 건가? 싶어서 환경 변수도 다시 설정해보면서 온갖 방법을 다 시도했다.
문제를 해결하기 위해 하나씩 의심하면서 점검하던 중,
VSCode에서 설치한 "Code Runner" 플러그인이 문제인가 의심이 들었다.
이 플러그인을 활성화하고 코드를 실행하면, 터미널에 아래와 같은 메시지만 뜨고 정작 크롤링 결과가 보이지 않았다.
[Running] python -u "c:\Users\pc\Desktop\testPy\test.py"
[Done] exited with code=0 in 0.416 seconds
[Running] python -u "c:\Users\pc\Desktop\testPy\test.py"
이 문제를 해결한 방법은 아주 간단했다.
Code Runner 플러그인을 삭제하고 VSCode를 재실행하는 것!
재실행 하고 다시 크롤링 코드를 실행해보니 정상적으로 결과가 출력되었다.
미루고 미뤘던 크롤링 공부를 드디어 해보게 되었습니다.
어렵고 복잡한줄 알고 계속 미뤘는데, 막상 해보니 재밌어서 진작 해볼걸 그랬네요 허허
읽어주셔서 감사합니다.
'공부 메모' 카테고리의 다른 글
| [HTTP] 네트워크 필수 개념 정리 (IP/TCP/UDP/PORT/DNS) (1) | 2025.03.28 |
|---|---|
| 유튜브 URL로 댓글 목록 크롤링하기 (0) | 2025.03.18 |
| Spring Boot 스프링부트 MySQL 연동 오류 해결법 (0) | 2023.11.10 |
| 벨로그(velog) & 티스토리(Tistory) 색 넣는 법 (0) | 2023.11.08 |
| 스프링부트 Spring Boot 500에러 해결 방법 (1) | 2023.11.07 |
웹 개발자가 되려면 크롤링은 어느정도 할 줄 알아야 한다고 생각합니다.
그래서 오늘은 크롤링에 대해 공부해보려고 합니다.
웹 크롤링이란?
웹 크롤링(Web Crawling)은 웹 사이트에서 데이터를 자동으로 수집하는 기술을 의미합니다.
이를 통해 웹 상의 다양한 데이터를 가져와 가공할 수 있죠.
주요 라이브러리
웹 크롤링을 하기 위한 보편적인 라이브러리 몇 가지만 소개하겠습니다.
| 라이브러리 | 기능 |
| requests | 웹 페이지 HTML 가져오기 |
| BeautifulSoup | HTML을 파싱(분석)하여 원하는 데이터 추출 |
| Selenium | 동적인 웹 사이트(JavaScript 기반) 크롤링 |
| pandas | 크롤링한 데이터를 저장하고 분석하는데 활용 |
| scrapy | 대규모 크롤링을 위한 프레임워크 |
정적 vs 동적?
웹 크롤링은 크게 정적 크롤링과 동적 크롤링으로 나눌 수 있습니다. 차이점은 웹 페이지의 내용이 어떻게 로드되는지에 따라 달라집니다.
1. 정적 크롤링 (Static Crawling)
정적 웹 페이지는 페이지의 모든 콘텐츠가 HTML 파일로 서버에서 클라이언트로 전송됩니다. 이 HTML 파일에는 페이지의 모든 텍스트, 이미지, 링크 등 필요한 정보가 포함되어 있습니다.
정적 크롤링은 페이지가 완전히 로드된 상태에서 HTML 코드만을 읽어들이는 방식입니다. JavaScript나 다른 클라이언트 코드가 실행되지 않아도 데이터를 바로 추출할 수 있습니다.
정적 페이지 예시: 블로그, 뉴스 사이트, 기업 웹사이트 페이지 등
2. 동적 크롤링 (Dynamic Crawling)
동적 웹 페이지는 JavaScript 등을 사용하여 페이지 로딩 후 추가적인 콘텐츠를 클라이언트 측에서 동적으로 로드하는 웹 페이지입니다. 즉, 서버에서 초기 HTML 파일만 보내고, 그 후에는 JavaScript 코드가 실행되어 페이지의 나머지 콘텐츠를 추가로 로드합니다.
동적 크롤링은 이 JavaScript로 생성된 콘텐츠까지도 크롤링해야 하므로, 크롤러가 페이지를 완전히 로드할 때까지 기다리고 JS를 실행할 수 있어야 합니다.
동적 페이지 예시: 소셜 미디어, 쇼핑몰, 지도 서비스 등
정적 크롤링 실습
입력한 키워드가 포함된 네이버 뉴스의 제목과 url을 가져오는 실습을 진행해보겠습니다.
먼저, 필요한 라이브러리 설치를 위해 VSCode의 터미널 창에 아래 명령어를 입력하여 라이브러리를 설치합니다.
pip install beautifulsoup4 requests
실습에 필요한 라이브러리를 import 해줍니다.
from bs4 import BeautifulSoup as bs
import requests
검색할 키워드를 입력받고 query 변수에 넣어줍니다.
query = input('검색할 키워드를 입력하세요: ')
네이버 뉴스 검색 URL에 사용자가 입력한 키워드를 넣어서 URL을 만들어줍니다.
url = 'https://search.naver.com/search.naver?where=news&sm=tab_jum&query='+'%s'%query
requests 패키지를 이용해 해당 URL에서 HTML 데이터를 가져옵니다.
가져온 HTML 문서를 문자열로 저장하여 html_txt 변수에 넣습니다.
response = requests.get(url)
html_text = response.text
BeautifulSoup 패키지로 파싱 후, 'soup' 변수에 저장합니다.
soup = bs(response.text, 'html.parser')
네이버 뉴스 페이지에서 기사 제목을 감싸고 있는 <a> 태그를 선택하여 news_titles 리스트에 저장합니다.
news_titles = soup.select("a.news_tit")# 뉴스 제목을 감싸고 있는 HTML 구조 예시
<a href="뉴스링크" class="news_tit" target="_blank" title="기사 제목">
기사 제목
</a>
<a> 태그 안의 텍스트(기사 제목)만 추출하여 출력합니다.
for i in news_titles:
title = i.get_text()
print(title)
뉴스 링크를 크롤링하기 위해 <a> 태그의 href 속성 값(뉴스 기사 URL)을 추출하여 출력합니다.
for i in news_titles:
href = i.attrs['href']
print(href)
정적 크롤링 - 전체 코드
from bs4 import BeautifulSoup as bs
import requests
# 검색할 키워드 입력
query = input('검색할 키워드를 입력하세요: ')
# 네이버 뉴스 검색 URL 생성
url = 'https://search.naver.com/search.naver?where=news&sm=tab_jum&query='+'%s'%query
# HTML 문서 가져오기
response = requests.get(url)
html_text = response.text
# HTML 파싱
soup = bs(response.text, 'html.parser')
# 뉴스 제목 크롤링
news_titles = soup.select("a.news_tit")
# 뉴스 제목 출력
for i in news_titles:
title = i.get_text()
print(title)
# 뉴스 URL 크롤링 출력
for i in news_titles:
href = i.attrs['href']
print(href)
동적 크롤링 실습
구글 트렌드 페이지에서 실시간 인기 검색어를 가져오는 실습을 해보겠습니다.
먼저, 필요한 라이브러리 설치를 위해 똑같이 아래 명령어를 입력하여 설치합니다.
pip install selenium
pip install webdriver-manager
실습에 필요한 라이브러리를 import 해줍니다.
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from webdriver_manager.chrome import ChromeDriverManager
import time
webdriver-manager 라이브러리를 사용하여 자동으로 크롬 드라이버를 다운로드하고, 서비스로 실행합니다.
크롬 브라우저를 자동으로 실행하여 driver 객체를 생성합니다. 이후 driver를 통해 브라우저를 제어할 수 있습니다.
service = Service(ChromeDriverManager().install())
driver = webdriver.Chrome(service=service)
구글 트렌드 페이지의 URL을 가져와줍니다.
driver.get(url)을 통해 Selenium WebDriver는 브라우저에서 해당 URL로 접속합니다.
url = "https://trends.google.com/trends/trendingsearches/daily"
driver.get(url)
페이지가 완전히 로드되도록 3초간 대기해줍니다.
time.sleep(3)
크롤링할 URL에 들어가서 F12를 누른 다음, Ctrl+Shift+C를 클릭하고, 인기 검색어 제목을 클릭하면, 해당 위치의 HTML을 확인할 수 있습니다. 여기서 class 태그의 값인 ".mZ3RIc"를 적어주면, 이에 해당하는 모든 요소들을 찾습니다.
search_keywords = driver.find_elements(By.CSS_SELECTOR, ".mZ3RIc")
serch_keywords 리스트에서 인덱스와 값을 함께 순회합니다. start=1로 설정했기 때문에 인덱스는 1부터 시작합니다.
print("@@구글 트렌드 인기 검색어@@")
for idx, keyword in enumerate(search_keywords, start=1):
print(f"{idx}. {keyword.text}")
브라우저를 종료하고 Selenium WebDriver 세션을 종료합니다.
driver.quit()
동적 크롤링 - 전체 코드
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from webdriver_manager.chrome import ChromeDriverManager
import time
# 크롬 드라이버 실행
service = Service(ChromeDriverManager().install())
driver = webdriver.Chrome(service=service)
# 구글 트렌드 페이지 접속
url = "https://trends.google.com/trends/trendingsearches/daily"
driver.get(url)
# 페이지 로딩 대기
time.sleep(3)
# 인기 검색어 크롤링
search_keywords = driver.find_elements(By.CSS_SELECTOR, ".mZ3RIc")
# 인기 검색어 리스트 출력
print("@@구글 트렌드 인기 검색어@@")
for idx, keyword in enumerate(search_keywords, start=1):
print(f"{idx}. {keyword.text}")
# 웹드라이버 종료
driver.quit()
막혔던 점
웹 크롤링을 공부하면서 직접 코드를 작성하고 실행해보는 과정에서 문제가 발생했다.
코드를 실행했을 때 결과가 터미널에 출력되지 않는 것이다.
처음에는 코드가 잘못된 줄 알고 여러 크롤링 예제들을 참고해서 고치고 또 고쳤다.
혹시 라이브러리가 정상적으로 설치되지 않은 건가? 싶어서 환경 변수도 다시 설정해보면서 온갖 방법을 다 시도했다.
문제를 해결하기 위해 하나씩 의심하면서 점검하던 중,
VSCode에서 설치한 "Code Runner" 플러그인이 문제인가 의심이 들었다.
이 플러그인을 활성화하고 코드를 실행하면, 터미널에 아래와 같은 메시지만 뜨고 정작 크롤링 결과가 보이지 않았다.
[Running] python -u "c:\Users\pc\Desktop\testPy\test.py"
[Done] exited with code=0 in 0.416 seconds
[Running] python -u "c:\Users\pc\Desktop\testPy\test.py"
이 문제를 해결한 방법은 아주 간단했다.
Code Runner 플러그인을 삭제하고 VSCode를 재실행하는 것!
재실행 하고 다시 크롤링 코드를 실행해보니 정상적으로 결과가 출력되었다.
미루고 미뤘던 크롤링 공부를 드디어 해보게 되었습니다.
어렵고 복잡한줄 알고 계속 미뤘는데, 막상 해보니 재밌어서 진작 해볼걸 그랬네요 허허
읽어주셔서 감사합니다.
'공부 메모' 카테고리의 다른 글
| [HTTP] 네트워크 필수 개념 정리 (IP/TCP/UDP/PORT/DNS) (1) | 2025.03.28 |
|---|---|
| 유튜브 URL로 댓글 목록 크롤링하기 (0) | 2025.03.18 |
| Spring Boot 스프링부트 MySQL 연동 오류 해결법 (0) | 2023.11.10 |
| 벨로그(velog) & 티스토리(Tistory) 색 넣는 법 (0) | 2023.11.08 |
| 스프링부트 Spring Boot 500에러 해결 방법 (1) | 2023.11.07 |